

El capítulo anterior de esta serie puede verse aquí.
El ordenador hablante
Uno de los campos de importancia en la aplicación de los ordenadores al tratamiento de las lenguas, es la conversión de texto a voz y viceversa.
El que un ordenador sea capaz de hablar y mantener una conversación como una persona es una tarea harto compleja y, hoy por hoy, estamos muy lejos de conseguirlo. Esta complejidad viene derivada, especialmente, del acto de comprender y generar mensajes. En todo acto comunicacional existen seis pasos fundamentales tal como se en la figura:
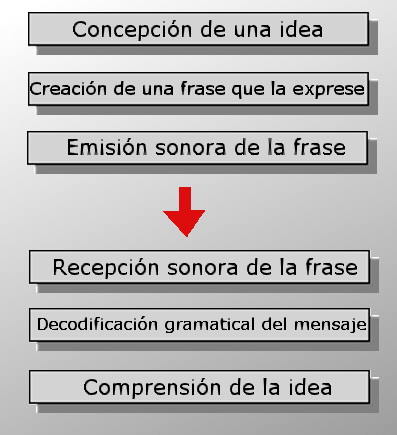
Los pasos extremos: imaginar una idea coherente y comprenderla están hoy por hoy lejos de la capacidad de una computadora. La inteligencia artificial podrá algún día llegar a imaginar algoritmos que realicen estas tareas en igualdad de condiciones con un humano pero no a fecha de hoy.
Respecto a los pasos intermedios, podríamos, en base al desarrollo computacional de las gramáticas formales, llegar a crear frases correctas y determinar si las oraciones recibidas son correctas. Pero de ahí a entender el significado va un largo camino.
Sin embargo, en donde sí se ha avanzado considerablemente es en los pasos centrales. Es decir, emitir electrónicamente los sonidos que conformen una frase de manera correcta y, asimismo, tener la capacidad de reconocer un mensaje vocal y traducirlo a una frase escrita, susceptible de ser analizada con un parser.
Los sistemas de tratamiento de voz tienen un amplio campo de aplicaciones, algunas de las cuales son ya casi de uso rutinario. Así, los mensajes emitidos en los aeropuertos, los mensajes automáticos que nos llegan por teléfono, algunos electrodomésticos que emiten mensajes de alerta, GPSs, los sistemas de ayuda a invidentes, etc. También en el ámbito del reconocimiento de voz, existen ya aplicaciones diarias como los que utilizan las compañías telefónicas para escuchar un mensaje de voz y convertirlo en mensaje de texto SMS con una calidad más que apreciable o los teléfonos y GPS que entiendes, al menos, una serie de mensajes limitados.
Sin duda, como decíamos en el capítulo 1 de esta serie, el futuro pasa porque la interacción con los ordenadores sea verbal, sin teclados ni ratones. Además de ser la forma comunicativa natural, el uso de la voz permite además la realización de otros trabajos de forma simultánea a dicha comunicación y permiten acceder a una gran cantidad de información en poco tiempo.
En el campo de la literatura, existe una potencial aplicación muy interesante que, hasta donde yo sé, no ha sido aún desarrollada más allá de experiencias de laboratorio: el teatro. Podemos imaginar que un autor de una obra de teatro podría probar cómo se escuchan sus textos antes de publicarlos. Un ordenador capaz no sólo de crear voces sino de matizarlas con expresión, con intención, con sentimiento, le permitiría al autor elegir la mejor forma de expresión, “oír” los diálogos antes de los ensayos con actores reales; saber cómo se escucharía su trabajo; determinar notas al margen para declamar de cierta manera que el autor “ya ha oído” antes en modo virtual; incluso proponer para el casting un tipo de voz determinado que el autor ya sabe que se adapta mejor al discurso porque ya lo ha oído virtualmente.
La conversión texto-voz
La conversión de un texto en voz se basa en sintetizar mediante la adecuada combinación de ondas, la voz humana. Para lograrlo existen tres técnicas principales:
· Codificación de onda sonora por concatenación
· Síntesis de difonos
· Síntesis paramétrica
· Síntesis por reglas
La idea de conseguir que una máquina simulara la voz es antigua. Existen relatos de personajes que lo intentaron a principios de milenio como Aurillac (1003) o Tocino de Roger (1250). En el siglo XVIII, Kratzenstein logró en Dinamarca reproducir vocales usando tubos de órgano especiales. Kampelen, por aquel entonces, logró crear una máquina que lograba reproducir palabras completas. En su libro Mechanismus der menschlichen Sprache nebst Beschreibung einer sprechenden Maschine (1791) incluyó varios dibujos para construirla. Un modelo se conserva hoy en día en un museo de Viena.

En 1837, Wheatsone produjo un modelo perfeccionado del de Kampelen y en 1857, Faber ideó la máquina Euphonia que simulaba aceptablemente algunas palabras.
En 1939 se presentó, disponiendo ya de electricidad, el sistema VODER que fue presentado en varias Ferias internacionales.

que mediante sistemas electromécanicos y manejado por operadores expertos que manejaban teclados similares a los de un piano para ir modificando las frecuencias y las entonaciones, conseguían un resultado pobre pero que, para la época, resultaba extraordinario. Puede oírse el resultado de un Voder aquí yaquí.
En 1961, Kelly de Juan y Kertsman utilizaron por primera vez un ordenador para sintetizar sonidos, lo que abrió las puertas a sistemas eficientes y realmente realistas para simular la voz humana
Al principio, se pensó que la conversión de un texto en voz sería tan sencillo como pre-grabar todas aquellas palabras que se desease emitir y luego, simplemente, concatenarlas en el orden adecuado.

Pronto surgió un primer problema. ¿Cuál era la unidad a considerar? ¿Deberíamos grabar palabras? ¿O sílabas? ¿frases completas? Si la unidad era grande (por ejemplo, una frase) la calidad del mensaje era muy buena con la entonación precisa y la unión entre palabras sonando de manera totalmente natural. Pero entonces era casi imposible tener un programa general porque es imposible pre-grabar los millones y millones de oraciones distintas que cualquier hablante puede generar, añadiendo además las diversas entonaciones posibles. Sería una labor titánica en el tiempo y casi imposible de manejar por la necesidad de memoria y potencia de cálculo requerida.
Si se elegía como unidad la palabra, entonces la flexibilidad aumentaba mucho porque cualquier frase podía emitirse concatenando las palabras adecuadas. Y la capacidad de memoria no era tan elevada porque, en la práctica, con veinte o treinta mil palabras (considerando flexiones verbales y de entonación) es posible mantener una amplia variedad de conversaciones. Pero los especialistas que trabajaban en este campo se dieron cuenta de que este aproximación al problema implicaba el no conseguir un habla natural porque la concatenación de las palabras sonaba artificial ya que era complicado simular las relaciones entre segmentos adyacentes que se producen en la realidad. En la vida real, las fronteras entre las palabras no son claras y existen solapamientos, alofonías, diafonías, semisílabas, modificación del sonido en función de las palabras adyacentes, etc.
Por último, si se elegía como unidad de trabajo la sílaba u otros sonidos básicos (semisílaba, difonema) se llegaba a disponer de total flexibilidad (cualquier palabra o frase, incluso las nuevas o los extranjerismos) puede ser formada mezclando las unidades y era muy fácil generar la base de datos porque con unos pocos miles de semifonemas podía caracterizarse cualquier lengua natural. Pero los problemas de concatenación se hacían aún más importantes para que sonara un discurso natural. Además, los alófonos son elementos abstractos que no existen en la lengua real y por tanto más complicados de tratar por algoritmos.
Puede decirse que todas estas posibilidades están abiertas. Así, en algunos electrodomésticos o algunos vehículos, la unidad es la frase porque el sistema sólo debe expresar unas pocas ideas previamente establecidas:
- Puerta derecha sin cerrar
- Programa de cocción finalizado
- Recoja su ticket
En otras aplicaciones, como por ejemplo, los mensajes flexibles en algunos aeropuertos, se usa como unidad una mezcla de frases (o conjunto de palabras) sueltas:
- El vuelo con destino a + Mallorca + está listo para embarcarse por la puerta número + dos
- Salida del vuelo + A+T+6+7+0+con destino a + Londres+ está listo para embarcar. Por favor diríjanse a la puerta número + seis.
En ocasiones a este sistema se le denomina síntesis específica para un dominio
Y en otras ocasiones se recurre a utilizar sólo fonemas que permiten la generación de cualquier frase de manera totalmente flexible.
Codificación de la onda sonora por concatenación
Como se trata de una técnica que casi siempre es necesaria, explicaremos primeramente la técnica del muestreo o sampling que permite convertir una onda continua (analógica) en un grupo discreto de valores que pueden tratarse digitalmente.
La voz, como cualquier sonido, es una onda continua generalmente compleja:

Podemos leer el valor de la amplitud de esta onda cada cierto tiempo (por ejemplo, cada milisegundo) de manera que tendremos una sucesión de valores discretos (digitales) que puestos unos tras otro simularán con bastante precisión la onda continua original:


En el ejemplo de la gráfica anterior, la onda continua analógica quedaría caracterizada por la serie de valores digital correspondiente a la amplitud en los momentos del muestreo. Y esta serie de números es ya perfectamente computerizable, modificable y calculable.
Es evidente que si el sampleado se hace cada mucho tiempo, la aproximación lograda será mala (pero requerirá circuitos electrónicos sencillos, lentos y baratos), mientras que si se hace a intervalos muy pequeños, la aproximación será excelente (pero la circuitería será rápida, compleja y costosa). El teorema de muestreo o Teorema de Nyquist establece que es posible capturar toda la información de la forma de onda si se utiliza una frecuencia de muestreo del doble de la frecuencia más elevada contenida en la forma de onda. En los sistemas telefónicos la velocidad de muestreo ha sido establecida a 8000 muestras por segundo pero en el muestreo de música es habitual llegar a frecuencia de 44000 por segundo.

Los conversores análogico-digitales (A/D) convierten la onda de entrada continua en una serie de valores concretos sucesivos. Los conversores digital-analógicos toman una serie sucesiva de valores digitales y reconstruyen la onda continua interpolando entre un valor y otro. Como se ve en la siguiente figura, cuantos más datos digitales existan la interpolación y reconstrucción de la onda será más precisa.

En la codificación de la onda sonora, se parte de conjuntos de valores digitales que describen la onda (bien sean fonemas, palabras o frases completas). Este sistema tiene la gran ventaja de que, si la frecuencia de muestreo es suficiente, se conserva la característica original de la voz del locutor y es un procedimiento barato.
La onda sonora se puede muestrear de varias maneras. Las más sencilla es el muestreo lineal que básicamente es la que hemos visto en las figuras anteriores y en donde la onda queda representada por una sucesión de valores finitos.
La cuantificación PCM (Pulse Code Modulation) muestrea la señal como hemos venido explicando y cuantifica cada muestra con un valor binario (por ejemplo, para 8 bits, entre 0 y 255). Entonces transforma este valor en un tren de pulsos proporcional al valor en base a una codificación binaria.

Una vez puestos todos los pulsos en continuidad, a la salida tendremos, por tanto, una señal de pulsos que será fiel reflejo de la onda analógica de entrada

La técnica DPCM (Differential Pulse Code Modulation) es similar pero tiene en cuenta que, en general, la amplitud de la onda no sufre variaciones abruptas sino que se desarrolla de manera bastante continua. En tal caso, basta codificar y memorizar la diferencia entre un valor y el anterior. Entonces, a partir de un único valor inicial se puede ir formando la curva sumando y restando las pequeñas variaciones sobre el anterior valor. Haciéndolo de esta manera los valores son siempre menores y por tanto requieren menos pulsos para codificarlos, necesitándose menos memoria y obteniendo un procesamiento más rápido.
En todos los casos, lo que finalmente tenemos es un corpus vocal extenso. En ciertos casos se usan los logotomas que son palabras ficticias de 3 sílabas de la que se extrae la central. Se logra, así, memorizar un sonido natural dentro de una palabra, no aislado. Por ejemplo, si grabásemos pa sólo, este sonido quedaría menos natural que si lo extraemos de un logotema ficticio como obpate
Síntesis de difonos
Un difono es el sonido que abarca desde la mitad de la realización de un fonema hasta la mitad de la realización del fonema siguiente. Con ello, se consigue incorporar a la unidad de síntesis la transición de sonido entre fonemas para que la posterior concatenación resulte más natural.
La síntesis por difonos usa una base de datos conteniendo todos los difonos que pueden aparecer en un lenguaje. El número de difonos en español es reducido con solo unos 800 elementos pero en alemán se precisan mínimamente 2500.
Síntesis paramétrica
En vez de memorizar miles de datos tal como se hace en el muestreo lineal, podemos emular la onda de voz mezclando sus formantes más importantes, los parámetros que definen la señal. Esto complica el procesado pero, por el contrario, permite simular con precisión las transiciones e interacciones mutuas entre formantes.
Así como en las técnicas anteriores grababan un valor de la onda sin atender a su procedencia ni a su formación, la síntesis paramétrica intenta recrearla mezclando una serie de parámetros que la recreen lo más aproximadamente posible. Así, la onda se recrea mediante una fuente de ondas básicas (sinusoidales) y unos filtros parametrizables que las van modificando hasta lograr la onda deseada. Se entiende que con un solo filtro podemos crear muchas ondas de salida tan sólo afinando los parámetros que afectan al funcionamiento del filtro.

* Los sintetizadores LPC (Linear Predictive Coding)
Se trata de un procedimiento matemático que permite predecir los valores futuros de un sistema lineal partiendo de los valores anteriores. En estos sistemas se hace pasar la onda original a través de un filtro con unos 15 o 20 pasos de alteración. El cálculo matemático permite conocer cómo se alterará la onda tras pasar por estos pasos, de modo que es posible calcular y predecir la salida en función de los parámetros introducidos a cada paso.
En un sistema de síntesis LPC se memorizan primeramente de las unidades a tratar (fonemas, palabras, etc) mediante el muestreo de los sonidos tomados con un micrófono. Entonces, se calculan – para cada uno de ellos- los valores de los parámetros del filtro que lograría reproducir este sonido. Una vez determinados tales parámetros se guardan. Cuando se requiere producir el sonido, se alteran las ondas puras de un generador al que se le envían los parámetros antes calculados y memorizados. Como resultado, se escucha la palabra deseada. Es evidente que el trabajo de preparación es importante pero, una vez hecho, sólo se requiere memorizar estos parámetros (no millones de sonidos) y la circuitería se reduce porque sólo son necesarios el filtro y el generador de ondas madre.
Existen circuitos integrados, preparados para un cierto idioma y tipo de voz, que incluyen el generador, el filtro y los parámetros almacenados en ROM.
* Los sintetizadores por formantes
Se llaman formantes al grupo de armónicos que caracterizan el sonido. Este sistema de sintetización es similar al anterior pero en vez de usar coeficientes que modifican los filtros se usan formantes. Normalmente, parten de una fuente de ondas madre y de tres filtros en serie o en paralelo que generan armónicos que, al combinarse, dan el sonido deseado.
La síntesis por formantes da muchas veces una voz robótica, como las de las películas de miedo, pero permiten una flexibilidad total.
Síntesis por reglas
En este caso han de determinarse una serie de reglas y pasos que, aplicadas sobre la onda de entrada, acaben por modificarla para ofrecer el sonido final deseado.
Estos pasos son, abreviadamente:
· Normalización que consiste en convertir todo el texto de entrada a palabras. Así, si aparecen números se convertirá su grafía a palabra (Son 3 niños -> Son tres niños), si hay acrónimos se convertirán a letras ( F.B.I. -> Efe be i), etc.
· Localización del acento fonético de cada palabra. Esto no es siempre sencillo para un ordenador. Si existe tilde, es evidente y debe seguirse su posición ( canto vs. cantó) pero en ocasiones no es directo y deben aplicarse las reglas de la gramática habituales de la lengua (cuándo se acentúa una palabra llana, una aguda, etc).
· Localización de los signos de puntuación que permitirán alargar los sonidos ligeramente o hacer pausas para poder simular la prosodia de la frase. O bien para dar el tono interrogativo a una pregunta, por ejemplo.
· Conversión de todas las palabras a fonemas. Se usa una tabla de 42 sonidos básicos que permiten descomponer casi cualquier palabra en cualquier idioma. En español las reglas que relacionan sonidos y letras son sencillas pero en inglés son más complicadas porque una misma letra puede tomar sonidos diferentes (cut vs. run).
· Una vez se tiene la larga secuencia de fonemas se adscriben a cada uno la longitud necesaria y la frecuencia necesaria para la prosodia, un poco más agudo o un poco más grave para obtener mayor naturalidad en el habla. Las reglas que determinan cómo deben ser la duración y frecuencia básica se dedujeron experimentalmente analizando miles de fonemas pronunciados con sentido por locutores. Se redujeron finalmente a una decena de ellas para la duración. Algunas para las vocales y otras para las consonantes. También se logró deducir algoritmos que definían reglas para la frecuencia que define la entonación.
· Aplicación de los parámetros que definen estas reglas a los filtros.
Prosodia
Adicionalmente, pueden existir modulos que filtren la voz generada para otorgarle un flujo musical acorde con el idioma, para que no suene robótico, uniforme, artificial. Esta es una tarea complicada que no está aún lograda en la mayoría de los sistemas.
Reconocimiento de voz
El proceso inverso a la síntesis de voz es el reconocimiento de la misma.
Este proceso se suele hacer en dos pasos.
a) Extracción de fonemas: Los fonemas son las unidades lingüísticas y sonoras más pequeñas en que puede dividirse un conjunto fónico. Por ejemplo, la palabra /casa/ , está formada por una serie de cuatro fonemas /c/+/a/+/s/+/a/. Para extraer los fonemas de la voz de entrada, la señal se analiza espectralmente vía transformadas de Fourier. Mediante un micrófono se graba la señal analógica que será compleja del estilo de la mostrada en la figura:
Reconocimiento de voz
El proceso inverso a la síntesis de voz es el reconocimiento de la misma.
Este proceso se suele hacer en dos pasos.
a) Extracción de fonemas: Los fonemas son las unidades lingüísticas y sonoras más pequeñas en que puede dividirse un conjunto fónico. Por ejemplo, la palabra /casa/ , está formada por una serie de cuatro fonemas /c/+/a/+/s/+/a/. Para extraer los fonemas de la voz de entrada, la señal se analiza espectralmente vía transformadas de Fourier. Mediante un micrófono se graba la señal analógica que será compleja del estilo de la mostrada en la figura:

El análisis por desarrollo de Fourier es una técnica matemática que permite descomponer una onda arbitraria compleja en suma de ondas sencillas (sinusoidales).

Así, en la figura podemos ver que a medida que vamos añadiendo ondas sinusoidales de diferente amplitud y diferente frecuencia, la onda final va cambiando hasta convertirse en cuadrada. Del mismo modo, puede convertirse en cualquier otra onda y el proceso inverso es un cálculo matemático dominado y del que existen eficientes algoritmos

b) Conversión de los fonemas en palabras identificables: este proceso se puede realizar con ayuda de métodos topológicos, probabilísticos y de redes neuronales.
DTW
La técnica DTW ( Dynamic Time Warping) o alineamiento temporal dinámico se basa en comparar la onda grabada con todas las plantillas de referencia memorizadas. Para ello, y aprovechando las pausas o zonas de menor amplitud, se va troceando la señal en unidades individuales que luego se comparan con los patrones.
Es evidente que casi nunca coincidirán los espectros patrones con los espectros grabados por lo que se recurre a calcular la distancia mínima en términos matemáticos para determinar qué patrón es el correcto.
Modelo de Markov
Se basan en el concepto de cadenas de Markov que se puede ver como una máquina de estados finitos en la que el estado siguiente depende únicamente del estado actual, y asociado a cada transición entre estados se produce un vector de parámetros. En reconocimiento de voz, las cadenas de Markov se encargan de ajustar los distintos fonemas captados a fonemas de palabras completas previamente establecidas, adquiridos por entrenamiento.
Redes neuronales
Que utiliza redes de nodos que pueden auto aprender en base a reponderar los pesos de cada nodo en el resultado final.
Algunos programas prácticos
En esta dirección puede utilizarse un programa en red que pronuncia de manera aceptable un texto que se introduce con el teclado.

Otro programa es SODELS que puede encontrarse aquí.
En este enlace tenemos Text-to-speech que hace un gran trabajo en inglés, incluido un avatar hablante (ver más adelante):

En este enlace pueden verse otros programas del mismo tipo.
Incluso el visor PDF de Adobe permite “leer” el texto.
Existen también programas profesionales. Uno, Natural Reader, puede verse aquí.
Avatares
En ocasiones, el programa que convierte el texto a voz se acompaña de un gráfico que simula a un hablante. Se trata normalmente de una cara que mueve los labios a medida que el sonido se emite. Estos avatares pueden ser más o menos elaborados para simular un diálogo real con un ordenador. Con la potencia de los programas actuales, su calidad y realismo mejoran constantemente. En el ejemplo anterior Text-to-Speech podía verse un pequeño avatar.
Este otro programa dispone de otro avatar:

Voki permite generar avatares:

to be continued....
(El capítulo siguiente de esta serie puede leerse en este enlace)
El actual mejor texto al software es Text Speaker. Tiene Pronunciación personalizable, lee nada en la pantalla, e incluso se habla recordatorios. Las voces paquetes están bien de precio y suenan muy humano. Se convierte fácilmente blogs, correos electrónicos, libros electrónicos, y más a MP3 o para escuchar al instante.
ResponderEliminar